2Core verbs for analytic pipelines utilising a database
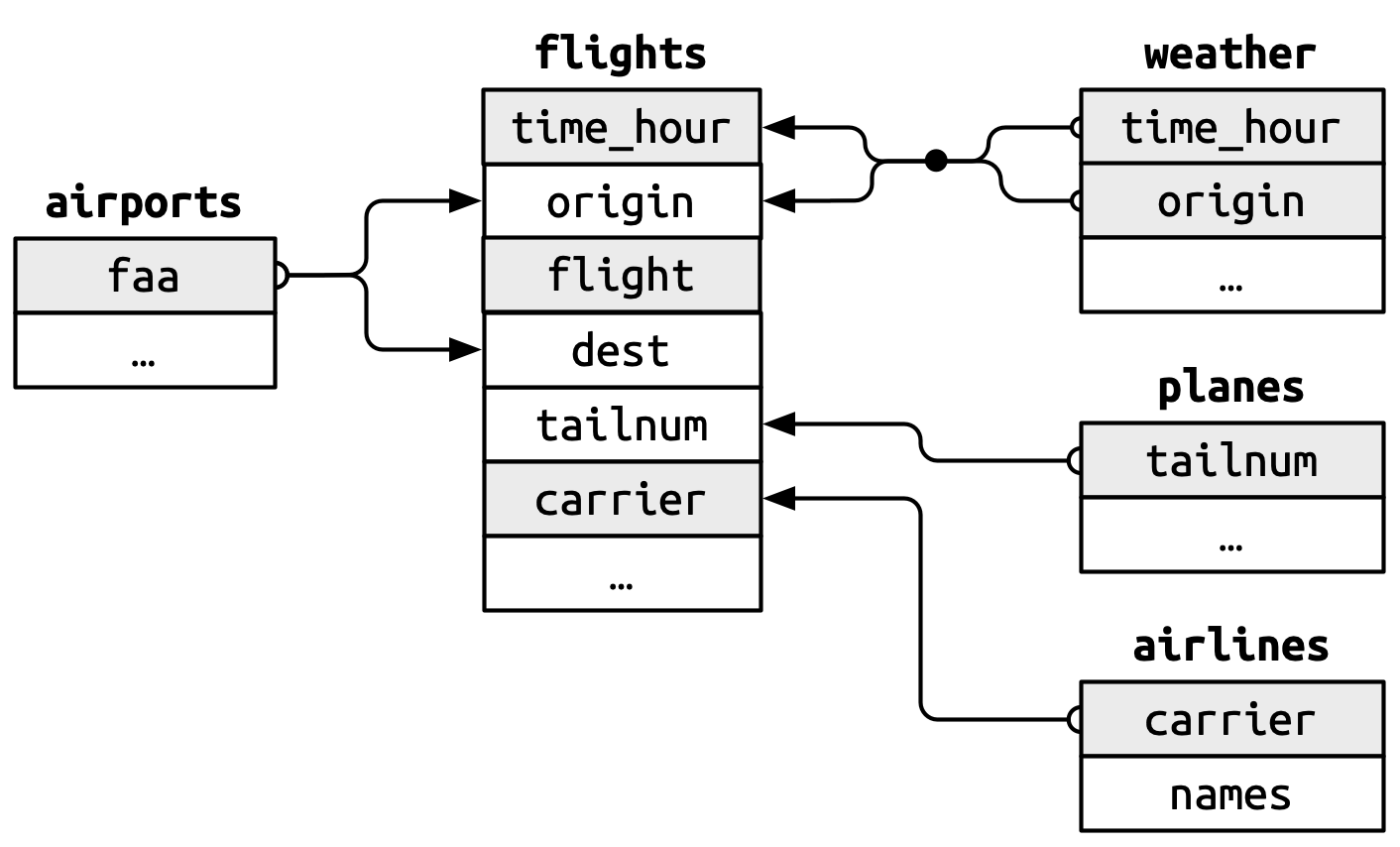
We saw in the previous chapter that we can use familiar dplyr verbs with data held in a database. In the last chapter we were working with just a single table which we loaded into the database. When working with databases we will though typically be working with multiple tables (as we’ll see later when working with data in the OMOP CDM format). For this chapter we will see more tidyverse functionality that can be used with data in a database, this time using the nycflights13 data. As we can see, now we have a set of related tables with data on flights departing from New York City airports in 2013.
Let’s load the required libraries, add our data to a duckdb database, and then create references to each of these tables.
For almost all analyses we want to go from having our starting data spread out across multiple tables in the database to a single tidy table containing all the data we need for the specific analysis. We can often get to our tidy analytic dataset using the below tidyverse functions (most of which coming from dplyr, but a couple also from the tidyr package). These functions all work with data in a database by generating SQL that will have the same purpose as if these functions were being run against data in R.
Important
Remember, until we use compute() or collect() (or printing the first few rows of the result) all we’re doing is translating R code into SQL.
By using the above functions we can use the same code regardless of whether the data is held in the database or locally in R. This is because the functions used above are generic functions which behave differently depending on the type of input they are given. Let’s take inner_join() for example. We can see that this function is a S3 generic function (with S3 being the most common object-oriented system used in R).
library(sloop)ftype(inner_join)
[1] "S3" "generic"
Among others, the references we create to tables in a database have tbl_lazy as a class attribute. Meanwhile, we can see that when collected into r the object changes to have different attributes, one of which being data.frame :
To see a little more on how we can use the above functions, let’s say we want to do an analysis of late flights from JFK airport. We want to see whether there is some relationship between plane characteristics and the risk of delay.
For this we’ll first use the filter() and select()dplyr verbs to get the data from the flights table. Note, we’ll rename arr_delay to just delay.
Now we’ll add plane characteristics from the planes table. We will use an inner join so that only records for which we have the plane characteristics are kept.
Note that our first query was not executed, as we didn’t use either compute() or collect(), so we’ll now have added our join to the original query.
Show query
<SQL>
SELECT LHS.*, seats
FROM (
SELECT dest, distance, carrier, tailnum, arr_delay AS delay
FROM flights
WHERE (NOT((arr_delay IS NULL))) AND (origin = 'JFK')
) LHS
INNER JOIN planes
ON (LHS.tailnum = planes.tailnum)
And when executed, our results will look like the following:
Getting to this tidy dataset has been done in the database via R code translated to SQL. With this, we can now collect our analytic dataset into R and go from there (for example, to perform locally statistical analyses which might not be possible to run in a database).